














Programa Internacional de Encuestas Sociales (ISSP)
¿Qué es el ISSP?
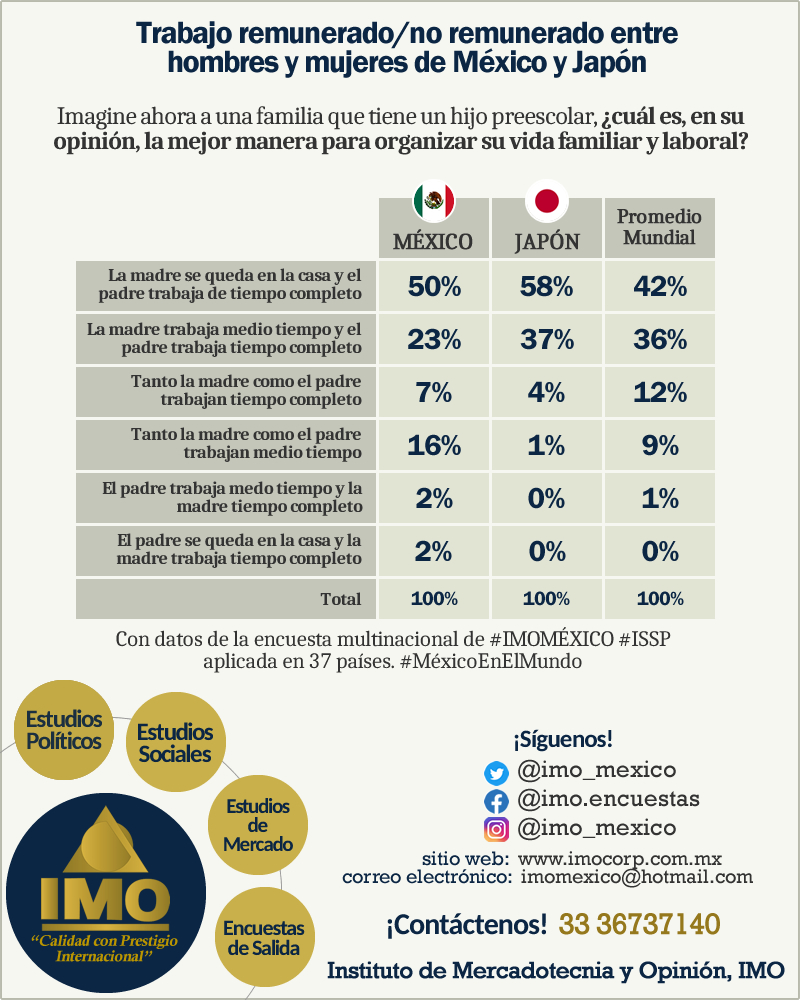
El ISSP es una organización independiente y multinacional que integra a instituciones dedicadas a la realización de encuestas con mayor prestigio dentro sus respectivos países y llevan a cabo encuestas anuales con un tema, objetivo y metodología comunes y cuyo trabajo se comparte al mundo. El ISSP ratificó en el año 2003 al Instituto de Mercadotecnia y Opinión (IMO) como el único representante de México dentro de este prestigioso programa.
IMO, Miembro y Único representante de México en el ISSP
EL IMO cuenta con la representación de México en el más importante Programa Internacional de Encuestas Sociales, el ISSP por sus siglas en inglés, en el cual están representados 44 países, lo que garantiza que las investigaciones del Instituto se manejen dentro de los niveles más altos a nivel mundial en los aspectos metodológicos del trabajo.(www.issp.org)
 “EL IMO cuenta con la representación de México en el más importante Programa Internacional de Encuestas Sociales lo que garantiza que las investigaciones del Instituto se manejen dentro de los niveles más altos a nivel mundial en los aspectos metodológicos del trabajo.” |